Siglo XXI: actualmente las bases de datos
tienen una amplia capacidad de almacenamiento y
están orientadas a que cumplan con el protocolo
OAI-PMH, los cuales permiten el almacenamiento de gran cantidad
de datos que tengan
mayor visibilidad y fácil acceso.

Base de datos y
sistema de gestión de base de datos
BASE DE DATOS
DEFINICION:
Son un conjunto de información relevante organizada de forma
sistemática que representan entidades y sus
interrelaciones, los datos almacenados pueden ser de diversa
índole, generalmente está estructurada por tablas y
estas a su vez por campos y registros,
además contiene procedimientos
necesarios para la
administración de los datos (Triggers, StoreProcedure,
etc.). Las bases de datos son importantes para la toma de
decisiones y para ejercer acciones,
actualmente se pueden considerar a los programas
informáticos como entes que manipulan datos (Sistemas
operativos, sgbd, etc.), otras definiciones:
Una base
de datos se puede definir como un conjunto de información
relacionada que se encuentra agrupada ó
estructurada.Un sistema de base de datos es una colección de
archivos interrelacionados.

Modelado de Base de datos,
mediante el modelo E-R
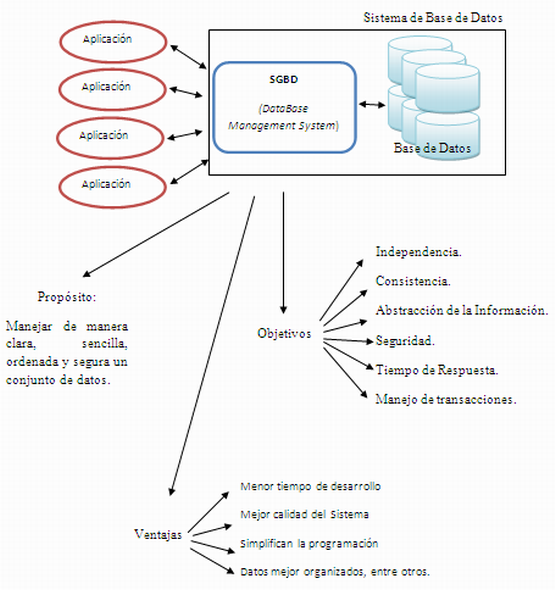
SISTEMA DE GESTION DE BASE DE DATOS (SGDB)
Un sistema de
gestión
de base de datos se puede definir como un conjunto de datos
interrelacionados y los programas necesarios para acceder y
manipularlos, cuyo objetivo
principal es almacenar y recuperar la información de una
base de datos de manera que sea fácil y eficiente a la
vez.
CARACTERISTICAS
Los SGBD tienen las siguientes mínimas
características:
Acceso a través de lenguajes de programación
estándar.Acceso por parte de múltiples usuarios.
Integridad de los datos.
Respaldo y recuperación (Backup).
Redundancia mínima.
Claves de seguridad, entre otras.
Aplicación de
los sistemas de base de datos
Los sistemas de base
de datos son ampliamente usados, especialmente en las
universidades, centros de investigación, banca de seguros,
líneas aéreas, telecomunicaciones, recursos
humanos, tiendas, supermercados, etc.
Como se puede observar, las base de datos forman parte
importante de la mayoría de empresas
actuales, las personas o usuarios no son consientes de su uso
debido a las interfaces, pero en el desarrollo
diario de los quehaceres estas ocupan los principales planos, de
hecho las base de datos forman parte de la vida de las
personas.
SGBD MÁS USADOS
Entre los sistemas gestores de base de datos más
usados, tenemos entre otros de acuerdo al tipo de licencia,
Libres:
MySQL: Perteneciente a Sun Microsystems (también
existe una versión no libre y más
completa).Postgresql.
Open Office Database: De Sun Microsystems.
SQLite: Con licencia GPL, entre otros.
Privativos
Oracle Database: Perteneciente a Oracle Corporation.
Fox Pro.
Magic.
Microsoft SQL sever.
Microsoft Access.
ADABAS: Perteneciente a IBM.
Paradox.
Sybase ASE, y Sybase ASA, entre otros.
A continuación se muestra algunas
comparaciones entre los principales SGBD:
Soporte del Sistema
operativo:

Objetos:


Modelos de
datos
Los modelos de
datos son una herramienta de abstracción que permiten
representar la realidad captando su semántica. Podemos clasificar a los modelos
de datos considerando diversos puntos, así tenemos:
De acuerdo a las categorías:
Modelos débilmente tipados: No es obligatorio que
los daros pertenezcan a categorías, sino pueden
existir por si mismos.Modelos estrictamente tipados: Los datos obligatoriamente
deben pertenecer a alguna categoría
En las base de datos se usan los modelos estrictamente
tipados, dado que permiten manejar una gran cantidad de datos al
agruparlos en categorías.
De acuerdo al nivel de abstracción:
Modelos conceptuales.
Modelos lógicos.
Modelos físicos.
En las base de datos se usan los modelos lógicos, donde
el principal modelo que se usa es el de
Entidad-Relación.
TIPOS DE ABSTRACCIÓN PARA EL DISEÑO DE BASE DE
DATOS
El proceso de
abstracción nos ayuda a modelar el mundo real, al hacer
que nos centremos en lo verdaderamente importa, en el diseño
de base de datos se utilizan cuatro tipos de abstracciones los
cuales son: Asociación,
generalización, agregación y
clasificación. Los cuales se aplican sólo o
combinados, a continuación se define cada tipo de
abstracción en el siguiente esquema, que trata de
representar las partes más importantes del objeto
"Bus", como son el
número de placa, la color, el numero
de llantas, etc. En una entidad llama Entidad_Bus y cuyas
características son los atributos.

La abstracción nos ayuda a concentrarnos en lo que
verdaderamente importa.
Los tipos de abstracción y su respectivo contravalor se
definen a continuación en el siguiente diagrama:

Definición
Un diagrama o modelo entidad-relación (a veces
denominado por su siglas, E-R) es una herramienta para
el modelado de datos de un sistema de
información. Estos modelos expresan entidades
relevantes para un sistema de información, sus
inter-relaciones y propiedades. En este modelo pueden
distinguirse los siguientes elementos:
a) ENTIDAD.
Se puede definir una entidad como cualquier objeto (real
o abstracto) que exista en la realidad y acerca del cual queremos
almacenar información en la base de datos.
O también representa una cosa u objeto del mundo
real con existencia independiente, es decir, se diferencia
unívocamente de cualquier otro objeto o cosa, incluso
siendo del mismo tipo. Presentamos un modelo:

b) INTERRELACIÓN.
Entendemos por interrelación una
asociación, vinculación o correspondencia entre
entidades. Denominaremos tipo de interrelación a la
estructura
genérica que describe un conjunto de relaciones.
Presentamos un modelo:

c) DOMINO Y VALOR.
Las distintas propiedades o características de un
tipo de entidad o de interrelación toman valores para
cada ejemplar de estas. El conjunto de posibles valores que puede
tomar una cierta característica se denomina dominio. Se
denomina dominio como un conjunto de valores homogéneos
con un nombre.
d) ATRIBUTO.
Cada una de las propiedades o características que
tiene un tipo de entidad o un tipo de interrelación se
denomina atributo, los atributos toman valores de una o varios
dominios, por tanto vale decir que el atributo le da una
determinada interpretación al dominio.
1. RESTRICCIONES:
Son reglas que deben mantener los datos almacenados en
la base de datos.
a) Correspondencia de
cardinalidades.
Dado un conjunto de relaciones en el que participan dos
o más conjuntos de
entidades, la correspondencia de cardinalidad indica el
número de entidades con las que puede estar relacionada
una entidad dada.
Dado un conjunto de relaciones binarias y los conjuntos
de entidades A y B, la correspondencia de cardinalidades puede
ser:
Uno a uno: Una entidad de A se relaciona
únicamente con una entidad en B y
viceversa.

Uno a varios: Una entidad en A se relaciona
con cero o muchas entidades en B. Pero una entidad en B se
relaciona con una única entidad en A.

Varios a uno: Una entidad en A se relaciona
exclusivamente con una entidad en B. Pero una entidad en B se
puede relacionar con 0 o muchas entidades en A.

Varios a varios: Una entidad en A se puede
relacionar con 0 o muchas entidades en B y
viceversa.

b) Restricciones de
participación.
Dado un conjunto de relaciones R en el cual participa un
conjunto de entidades A, dicha participación puede ser de
dos tipos:
Total: Cuando cada entidad en A participa en
al menos una relación de R.Parcial: Cuando al menos una entidad en A NO
participa en alguna relación de R
c) Claves.
Es un subconjunto del conjunto de atributos comunes en
una colección de entidades, que permite identificar
unívocamente cada una de las entidades pertenecientes a
dicha colección. Asimismo, permiten distinguir entre
sí las relaciones de un conjunto de relaciones.
Dentro de los conjuntos de entidades existen los
siguientes tipos de claves:
Superclave: Es un subconjunto de atributos
que permite distinguir unívocamente cada una de las
entidades de un conjunto de entidades. Si otro atributo unido
al anterior subconjunto, el resultado seguirá siendo
una superclave.Clave candidata: Dada una superclave, si
ésta deja de serlo removiendo únicamente uno de
los atributos que la componen, entonces ésta es una
clave candidata.Clave primaria: Es una clave candidata,
elegida por el diseñador de la base de datos, para
identificar unívocamente las entidades en un conjunto
de entidades.
Diagrama
entidad-relación
La estructura lógica
general de una base de datos se puede expresar
gráficamente mediante un diagrama E-R. Los diagramas son
simples y claros, cualidades que pueden ser responsables del
amplio uso del modelo E-R. Tal diagrama consta de los siguientes
componentes principales:
a) Rectángulos, que representan
conjuntos de entidades.b) Elipses, que representan
atributosc) Rombos, que representan
relaciones.d) Líneas, que unen atributos a
conjuntos de entidades y conjuntos de entidades a conjuntos
de relaciones.e) Elipses dobles, que representan
atributos multivalorados.f) Elipses discontinuas, que denotan
atributos derivados.g) Líneas dobles, que indican
participación total de una entidad en un conjunto de
relaciones.h) Rectángulos dobles, que
representan conjuntos de entidades débiles
Como ejemplo ilustrativo mostramos un
diagrama:

MODELO RELACIONAL
Estructura de base de
datos relacionales
Una base de datos relacional consiste en un conjunto de
tablas, a cada una de las cuales se le asigna un nombre
exclusivo.
Cada fila de la tabla representa una relación
entre un conjunto de valores. Dado que cada tabla es un conjunto
de dichas relaciones, hay una fuerte correspondencia entre el
concepto de
tabla y el concepto matemático de relación, del que
toma su nombre el modelo de datos relacional.
BASE DE DATOS
RELACIONALES
Una base de datos relacional es un repositorio
compartido de datos. Para hacer disponibles los datos de una base
de datos relacional a los usuarios hay que considerar varios
aspectos. Uno es la forma en que los usuarios solicitan los
datos: ¿cuáles son los diferentes lenguajes de
consulta que usan?
1. CARACTERÍSTICAS:
Presentamos las siguientes
características:
Una base de datos relacional se compone de varias
tablas o relaciones.No pueden existir dos tablas con el mismo
nombre.Cada tabla es a su vez un conjunto de registros,
filas o tuplas.Cada registro representa un objeto del mundo
real.Cada una de estos registros consta de varias
columnas, campos o atributos.No pueden existir dos columnas con el mismo nombre
en una misma tabla.Los valores almacenados en una columna deben ser del
mismo tipo de dato.Todas las filas de una misma tabla poseen el mismo
número de columnas.No se considera el orden en que se almacenan los
registros en las tablas.No se considera el orden en que se almacenan las
tablas en la base de datos.La información puede ser recuperada o
almacenada por medio de sentencias llamadas
consultas.
2. ESTRUCTURA:
La base de datos se organiza en dos marcadas secciones;
el esquema y los datos (o instancia). El esquema es la
definición de la estructura de la base de datos y
principalmente almacena los siguientes datos:
El nombre de cada tabla
El nombre de cada campo
El tipo de dato de cada campo
La tabla a la que pertenece cada campo
Las bases de datos relacionales pasan por un proceso al
que se le conoce como normalización, el resultado de dicho
proceso es un esquema que permite que la base de datos sea usada
de manera óptima. Los datos o instancia es el contenido de
la base de datos en un momento dado. Es en si, el contenido de
todos los registros.
3. VENTAJAS Y DESVENTAJAS:
Ventajas
Provee herramientas que garantizan evitar la
duplicidad de registros.Garantiza la integridad referencial, así, al
eliminar un registro elimina todos los registros relacionados
dependientes.Favorece la normalización por ser más
comprensible y aplicable.Desventajas
Presentan deficiencias con datos gráficos,
multimedia, CAD y sistemas de información
geográfica.No se manipulan de forma manejable los bloques de
texto como tipo de dato.
SQL (LENGUAJE
ESTRUCTURADO DE CONSULTAS)

El SQL es
el lenguaje
estándar ANSI/ISO de
definición, manipulación y control de bases
de datos relacionales. Es un lenguaje declarativo: sólo
hay que indicar qué se quiere hacer. En cambio, en los
lenguajes procedimentales es necesario especificar cómo
hay que hacer cualquier acción
sobre la base de datos. El SQL es un lenguaje muy parecido al
lenguaje natural; concretamente, se parece al inglés,
y es muy expresivo. Por estas razones, y como lenguaje
estándar, el SQL es un lenguaje con el que se puede
acceder a todos los sistemas relacionales comerciales. Una de sus
principales características es el manejo del algebra y el
cálculo
relacional que permiten efectuar consultas con el fin de
recuperar de una forma sencilla información de interés de
una base de datos, así como también hacer cambios
sobre ella.
El modelo relacional tiene como estructura de
almacenamiento de los datos las relaciones. La intensión o
esquema de una relación consiste en el nombre que hemos
dado a la relación y un conjunto de atributos. La
extensión de una relación es un conjunto de Tuplas,
trabajar con SQL esta nomenclatura
cambia es decir:
Hablaremos de tablas en lugar de
relaciones.Hablaremos de columnas en lugar de
atributos.Hablaremos de filas en lugar de tuplas.
Orígenes y
evolución
En 1970 E. F. Codd propone el modelo relacional y
asociado a este un sublenguaje de acceso a los datos basado en el
cálculo de predicados. Basándose en estas ideas,
los laboratorios de IBM definen el lenguaje SEQUEL (Structured
English Query Language) que más tarde sería
ampliamente implementado por el SGBD (Sistemas Gestores de Bases
de Datos) experimental System R, desarrollado en 1977
también por IBM. Sin embargo, fue Oracle quien
lo introdujo por primera vez en 1979 en un programa
comercial. El SEQUEL terminaría siendo el predecesor de
SQL, siendo éste una versión evolucionada
del primero. El SQL pasa a ser el lenguaje por excelencia
de los diversos SGBD relacionales surgidos en los años
siguientes y es por fin estandarizado en 1986 por el ANSI, dando
lugar a la primera versión estándar de este
lenguaje, el "SQL-86" o "SQL1". Al año siguiente este
estándar es también adoptado por la ISO. En la
actualidad el SQL es el estándar de facto de la
inmensa mayoría de los SGBD comerciales. Y, aunque la
diversidad de añadidos particulares que incluyen las
distintas implementaciones comerciales del lenguaje es amplia, el
soporte al estándar SQL-92 es general y muy
amplio.
CARACTERISTICAS PRINCIPALES
El SQL es un lenguaje de acceso a bases de datos que
explota la flexibilidad y potencia de los
sistemas relacionales permitiendo gran variedad de operaciones en
éstos últimos. Es un lenguaje declarativo de "alto
nivel" o "de no procedimiento",
que gracias a su fuerte base teórica y su
orientación al manejo de conjuntos de registros, y no a
registros individuales, permite una alta productividad en
codificación y la orientación a
objetos. De esta forma una sola sentencia puede equivaler a uno o
más programas que utilizas en un lenguaje de bajo nivel
orientado a registro.
La estructura básica de SQL consiste en tres
clausulas, select, from y where, de las cuales se define
brevemente:
SELECT: corresponde a la operación
proyección del algebra relacional, y se usa
para mostrar los atributos deseados de una
consulta.FROM: corresponde a la
operación producto cartesiano del algebra
relacional Lista las relaciones que deben ser analizadas en
la evaluaciónWHERE: corresponde al predicado
selección del algebra relacional, es un
predicado que engloba a los atributos de las relaciones que
aparecen en la clausula from.

Además SQL permite hacer las siguientes
operaciones:
Operación De Renombramiento: SQL proporciona
un mecanismo para renombrar tanto relaciones como atributos.
Para ello utiliza la cláusula as, que tiene la
forma siguiente: nombre-antiguo as nombre-nuevoOperación Sobre Cadenas: La
operación más usada sobre cadenas es el encaje
de patrones, para el que se usa el operador
like.Orden En La Presentación: SQL
ofrece al usuario cierto control sobre el orden en el cual se
presentan las tuplas de una relación. La
cláusula order by hace que las tuplas
resultantes de una consulta se presenten en un cierto
orden.
SENTENCIAS PARA DEFINICION DE DATOS
CREATE: Este comando crea un objeto dentro de
la base de datos. Puede ser una tabla, vista, índice,
trigger, función, procedimiento o cualquier otro
objeto que el motor de la base de datos soporte.

ALTER: Este comando permite modificar la
estructura de un objeto. Se pueden agregar/quitar campos a
una tabla, modificar el tipo de un campo, agregar/quitar
índices a una tabla, modificar un trigger,
etc.DROP: Este comando elimina un objeto de la
base de datos. Puede ser una tabla, vista, índice,
trigger, función, procedimiento o cualquier otro
objeto que el motor de la base de datos soporte. Se puede
combinar con la sentencia ALTER.TRÚNCATE: Este comando trunca todo el
contenido de una tabla. La ventaja sobre el comando DELETE,
es que si se quiere borrar todo el contenido de la tabla, es
mucho más rápido, especialmente si la tabla es
muy grande, la desventaja es que TRUNCATE solo sirve cuando
se quiere eliminar absolutamente todos los registros, ya que
no se permite la cláusula WHERE.

SENTENCIAS PARA LA MANIPULACIÓN DE
DATOS
Una vez creada la base de datos con sus tablas, debemos
poder
insertar, modificar y borrar los valores de
las filas de las tablas. Para poder hacer esto, el SQL nos ofrece
las siguientes sentencias: INSERT para insertar,
UPDATE para modificar y DELETE para
borrar.

INSERT: Una sentencia INSERT de SQL
agrega uno o más registros a una (y sólo una)
tabla en una base de datos relacional.UPDATE: Una sentencia UPDATE de SQL es
utilizada para modificar los valores de un conjunto de
registros existentes en una tabla.DELETE: Una sentencia
DELETE de SQL borra cero o más
registros existentes en una tabla,
VISTAS
Una vista en SQL se define utilizando la orden
"create view". Para definir una vista se le debe dar un
nombre y se debe construir la consulta que genere dicha vista. La
forma de la orden create view es la siguiente:
create view v as expresión
de consulta
TRANSACCIONES
Una transacción es parte de las sentencias de
control y consiste en una secuencia de instrucciones de consulta
y actualizaciones. La norma SQL especifica que una
transacción comienza implícitamente cuando se
ejecuta una instrucción SQL. Una de las siguientes
instrucciones SQL debe finalizar la
transacción:
Commit work compromete la transacción
actual; es decir, hace que los cambios realizados por la
transacción sean permanentes en la base de
datos.Rollback work causa el retroceso de la
transacción actual; es decir, deshace todas las
actualizaciones realizadas por las instrucciones SQL de la
transacción; así, el estado de la base de datos
se restaura al que existía previo a la
ejecución de la transacción.
TIPOS DE DATOS EN SQL
Luego de crear una Base de Datos, para crear las tablas,
sin embargo, se deben definir previamente los tipos de datos
que serán definidos para cada columna. Un tipo de dato es
un atributo que especifica cómo serán los datos que
pueden ser almacenados en una columna, parámetro, o
variable.
A. PROVISTOS POR EL SISTEMA:



Para definir mejor los tipos de datos
consideramos:
char (n) es una cadena de caracteres
de longitud fija, con una longitud n especificada
por el usuario. También se puede utilizar la palabra
completa character.varchar (n) es una cadena de
caracteres de longitud variable, con una longitud n
especificada por el usuario. También se puede utilizar
la forma completa character varying.int es un entero (un subconjunto finito de
los enteros, que es dependiente de la máquina).
También se puede usar la palabra completa
integer.smallint es un entero pequeño (un
subconjunto del dominio de los enteros, también
dependiente de la máquina).numeric (p,d) es un
número en coma flotante, cuya precisión la
especifica el usuario. El número está formado
por p dígitos (más el signo), y de
esos p dígitos, d pertenecen a la
parte decimal. Así, numeric (3,1) permite que
el número 44,5 se almacene exactamente, mientras que
los números 444,5 y 0,32 no se pueden almacenar
exactamente en un campo de este tipo.real, double precision son respectivamente
números en coma flotante y números en coma
flotante de doble precisión, con precisión
dependiente de la máquina.float (n) es un número en
coma flotante, cuya precisión es de al menos
n dígitos.date es una fecha del calendario, que
contiene un año (de cuatro dígitos), un mes y
un día del mes.time es la hora del día, expresada en
horas, minutos y segundos. Se puede usar una variante,
time (p), para especificar el número
de dígitos decimales para los segundos (el
número predeterminado es 0). También es posible
almacenar la información del uso horario junto al
tiempo.timestamp es una combinación de date y
time. Se puede usar una variante, timestamp(p), para
especificar el número de dígitos decimales para
los segundos (el número predeterminado es
6).
B. DECLARADOS POR EL USUARIO:
En algunos SGBD como SQL Server es
posible definir un tipo de dato propio (del usuario), Los tipos
de datos definidos por el usuario pueden ser usados en varias
tablas que deban guardar el mismo tipo de dato en una columna y
cuando se necesita asegurar que estas columnas tengan exactamente
el mismo tipo de dato, longitud y capacidad de aceptar nulos. Por
ejemplo, un tipo de datos definido por el usuario llamado
codigo_postal podría ser creado en base al tipo
char.
Cuando se crea un tipo de dato definido por el usuario,
se deben proveer los siguientes parámetros:
C. Nombre
D. Tipo de datos del sistema sobre el que se
basa el nuevo tipo de dato.E. Anulabilidad (si el tipo de dato permite
valores nulos).
Cuando la anulabilidad no es explícitamente
definida, se toma por defecto la configuración de nulos
ANSI para la base de datos o conexión.
DESENCADENANTES (TRIGGERS)
Los desencadenantes, también conocidos como
disparadores, (triggers en inglés) son definidos sobre la
tabla en la que opera la sentencia INSERT, los desencadenantes
son evaluados en el contexto de la operación.
Desencadenantes BEFORE INSERT permiten la modificación de
los valores que se insertará en la tabla. Desencadenantes
AFTER INSERT no puede modificar los datos de ahora en adelante,
pero se puede utilizar para iniciar acciones en otras tablas, por
ejemplo para aplicar mecanismos de auditoría.
STORED PROCEDURE (PROCEDIMIENTOS ALMACENADOS)
Son sentencias o procedimientos que residen en la misma
base de datos, y que para acceder a ellas solo deben ser
invocadas
Otros lenguajes
relacionales
SQL es el lenguaje relacional de mayor influencia
comercial. Sin embargo exiten otros lenguajes no muy conocidos
pero que son importantes: QBE (Query-by-Example) y Datalog. A
diferencia de SQL, QBE es un lenguaje gráfico donde las
consultas parecen tablas. QBE y sus variantes se usan ampliamente
en sistemas de bases de datos para computadoras
personales. Datalog tiene una sintaxis derivada del lenguaje
Prolog. Aunque actualmente no se usa de forma comercial, Datalog
se ha utilizado en el desarrollo de diversos sistemas de bases de
datos.
Base de datos
orientados a objetos
1. MODELO DE DATOS ORIENTADOS A
OBJETOS.
A continuación presentaremos los conceptos
principales del modelo de datos orientados a objetos:
a) Estructura de
objetos:
Hablando en general, los objetos se corresponden con las
entidades del modelo E-R (entidad-relación). El paradigma
orientado a objetos está basado en el encapsulamiento de
los datos y del código
relacionado con cada objeto en una sola unidad cuyo contenido no
es visible desde el exterior. Conceptualmente, todas las
interacciones entre cada objeto y el resto del sistema se
realizan mediante mensajes. Por tanto, la interfaz entre cada
objeto y el resto del sistema se define mediante un conjunto de
mensajes permitidos. En general, cada objeto está asociado
con:
Un conjunto de variables que contiene
los datos del objeto; las variables se corresponden con los
atributos del modelo E-R.Un conjunto de mensajes a los que responde; cada
mensaje puede no tener parámetros, tener uno o
varios.Un conjunto de métodos, cada uno
de los cuales es código que implementa un mensaje; el
método devuelve un valor como respuesta al
mensaje.
El término mensaje en un entorno orientado a
objetos no implica el uso de mensajes físicos en redes
informáticas.
Por el contrario hace referencia al intercambio de
solicitudes entre los objetos. Se utiliza a veces la
expresión invocar a un método
para denotar el hecho de enviar un mensaje a un objeto y la
ejecución del método correspondiente.
Se puede explicar la razón del uso de este
enfoque considerando las entidades empleado de una base de datos
bancaria. Supongamos que el sueldo anual de cada empleado se
calcula de diferente manera para todos los empleados. Por
ejemplo, puede que los jefes obtengan una prima en función de
los resultados del banco, mientras
que los cajeros reciben una prima en función de las horas
que hayan trabajado. Se puede (en teoría)
encapsular el código para calcular su sueldo con cada
empleado en forma de método que se ejecute en respuesta a
un mensaje de sueldo-anual.
Todos los objetos empleados responden al mensaje
sueldo-anual, pero lo hacen de manera diferente. Al encapsular
con el objeto empleado la información sobre el
cálculo de su sueldo anual, todos los objetos empleados
presentan la misma interfaz. Dado que la única interfaz
externa presentada por cada objeto es el conjunto de mensajes a
los que responde, resulta posible modificar las definiciones de
los métodos y
de las variables sin
afectar al resto del sistema. La posibilidad de modificar la
definición de un objeto sin afectar al resto del sistema
se considera una de las mayores ventajas del paradigma de la
programación
orientada a objetos.
Los métodos de cada objeto pueden clasificarse
como sólo de lectura o de
actualización. Los métodos sólo de lectura
no afectan al valor de las
variables de los objetos, mientras que los métodos de
actualización sí pueden modificarlo. Los mensajes a
los que responde cada objeto pueden clasificarse de manera
parecida como sólo de lectura o de actualización,
según el método que los implemente.
Los atributos derivados de las entidades del modelo E-R
pueden expresarse en el modelo orientado a objetos como mensajes
sólo de lectura. Por ejemplo, el atributo derivado
antigüedad de una entidad empleado puede expresarse como el
mensaje antigüedad de un objeto empleado. El método
que implemente los mensajes, puede determinar la antigüedad
restando la fecha-alta del empleado de la fecha
actual.
Hablando con rigor, en el modelo orientado a objetos hay
que expresar cada atributo de las entidades como una variable y
un par de mensajes del objeto correspondiente. La variable se
utiliza para guardar el valor del atributo, uno de los mensajes
se utiliza para leer el valor del atributo y el otro mensaje se
utiliza para actualizar ese valor. Por ejemplo, el atributo
dirección de la entidad empleado puede
representarse mediante: hay que expresar cada atributo de las
entidades como una variable y un par de mensajes del objeto
correspondiente. La variable se utiliza para guardar el valor del
atributo, uno de los mensajes se utiliza para leer el valor del
atributo y el otro mensaje se utiliza para actualizar ese valor.
Por ejemplo, el atributo dirección de la entidad empleado
puede representarse mediante:
Una variable dirección.
Un mensaje obtener-dirección cuya respuesta
sea la dirección.Un mensaje establecer-dirección, que necesita
un parámetro nueva dirección, para actualizar
la dirección.
Sin embargo, en aras de la sencillez, muchos modelos
orientados a objetos permiten que las variables se lean o se
actualicen de manera directa, sin necesidad de definir los
mensajes para ello.
b) Clases de
objetos:
Generalmente, en una base de datos hay muchos objetos
similares. Por similar se entiende que responden a los mismos
mensajes, utilizan los mismos métodos y tienen variables
del mismo nombre y del mismo tipo.
Sería un derroche definir por separado cada uno
de estos objetos. Por tanto, los objetos parecidos se agrupan
para formar una clase.
El concepto de clase del modelo orientado a objetos se
corresponde con el concepto de entidad del modelo E-R. Algunos
ejemplos de clases en la base de datos bancaria son los
empleados, los clientes, las
cuentas y los
préstamos.
c) Herencia:
Los esquemas de las bases de datos orientadas a objetos
suelen necesitar gran número de clases. Sin embargo,
varias de las clases son parecidas entre sí. Por ejemplo,
supóngase que se tiene una base de datos orientada a
objetos en la aplicación bancaria. Cabe esperar que la
clase de los clientes del banco sea parecida a la clase de los
empleados en que ambas definan variables para nombre,
dirección, etcétera. Sin embargo, hay algunas
variables específicas de los empleados (sueldo, por
ejemplo) y otras específicas de los clientes
(interés-préstamo, por ejemplo). Sería
conveniente definir una representación de las variables
comunes en un solo lugar. Esto sólo puede hacerse si se
combinan los empleados y los clientes en una sola
clase.
Para permitir la representación directa de los
parecidos entre las clases hay que ubicarlas en una
jerarquía de especializaciones. Por ejemplo, se puede
decir que empleado es una especialización de persona, dado que
el conjunto de los empleados es un subconjunto del conjunto de
personas. Es decir, todos los empleados son personas. De manera
parecida, cliente es una
especialización de persona. Ilustrando el ejemplo
tenemos:

d) Herencia múltiple:
En la mayor parte de los casos una organización de clases con estructura de
árbol resulta adecuada para describir las aplicaciones; en
la
organización con estructura de árbol, cada
clase puede tener a lo sumo una superclase. Sin embargo, hay
situaciones que no pueden representarse bien en una
jerarquía de clases con estructura de
árbol.
La herencia
múltiple permite a las clases heredar variables y
métodos de múltiples superclases. La
relación entre clases y subclases se representa mediante
un grafo acíclico dirigido en el que las clases pueden
tener más de una superclase.

e) Identidad de los objetos:
Los objetos de las bases de datos orientadas a objetos
suelen corresponder a entidades del sistema modelado por la base
de datos. Las entidades conservan su identidad
aunque algunas de sus propiedades cambien con el tiempo. Este
concepto de identidad no se aplica a las tuplas de las bases de
datos relacionales.
Presentamos a continuación algunos ejemplos de
identidad:
Valor. Se utiliza un valor de datos como
identidad. Esta forma de identidad se utiliza en los sistemas
relacionales. Por ejemplo, el valor de la clave primaria de
una tupla identifica a la tupla.Nombre. Se utiliza como identidad un nombre
proporcionado por el usuario. Esta forma de identidad suele
utilizarse para los archivos en los sistemas de archivos.
Cada archivo recibe un nombre que lo identifica de manera
unívoca, independientemente de su
contenido.Incorporada. Se incluye el concepto de
identidad en el modelo de datos o en el lenguaje de
programación y no hace falta que el usuario
proporcione ningún identificador. Esta forma de
identidad se utiliza en los sistemas orientados a objetos.
Cada objeto recibe del sistema de manera automática un
identificador en el momento en que se crea.
La identidad de los objetos es una noción
conceptual; los sistemas reales necesitan un mecanismo
físico que identifique los objetos de manera
unívoca. Para los seres humanos se suelen utilizar como
identificadores los nombres, junto con otra información
como la fecha y el lugar de nacimiento. Los sistemas orientados a
objetos proporcionan el concepto de identificador del objeto para
identificar a los objetos. Los identificadores de los objetos son
únicos; es decir, cada objeto tiene un solo identificador
y no hay dos objetos que tengan el mismo identificador
Base de datos
relacionales orientados a objetos
1) RELACIONES ANIDADAS:
El modelo relacional anidado es una
extensión del modelo relacional en la que los dominios
pueden ser atómicos o de relación. Por tanto, el
valor de las tuplas de los atributos puede ser una
relación, y las relaciones pueden guardarse en otras
relaciones. Los objetos complejos, por tanto, pueden
representarse mediante una única tupla de las relaciones
anidadas. Si se consideran las tuplas de las relaciones anidadas
como elementos de datos, se tiene una correspondencia uno a uno
entre los elementos de datos y los objetos de la vista de la base
de datos del usuario.
Las relaciones anidadas se ilustran mediante un ejemplo
extraído de una biblioteca.
Considérese que para cada libro se
almacena la información siguiente:
Título del libro.
Lista de autores.
Editorial.
Lista de palabras clave.

Puede verse que, si se define una relación para
la información anterior, varios de los dominios
serán no atómicos.
Autores. Un libro puede tener varios autores.
No obstante, puede que se desee hallar todos los documentos
entre cuyos autores estuviera Santos. Por tanto, hay
interés en una parte del elemento del dominio
«conjunto de autores».Palabras clave. Si se guarda un conjunto de
palabras clave de cada documento se espera poder recuperar
todos los documentos cuyas claves incluyan una o varias de
las palabras clave especificadas. Por tanto, se considera que
el dominio de la lista de palabras clave no es
atómico.Editorial. A diferencia de palabras clave y
autores, editorial no tiene un dominio de tipo conjunto. Sin
embargo, se puede considerar que editorial consiste en los
subcampos nombre y sucursal. Esta manera de considerarlo hace
que el dominio de editorial no sea atómico.
2) TIPOS
COMPLEJOS:
El modelo de datos orientado a objetos ha creado la
necesidad de características como la herencia y las
referencias a los objetos.
Los sistemas de tipos complejos y la programación orientada a objetos permiten
que los conceptos del modelo E-R, como la identidad de las
entidades, los atributos multivalorados y la
generalización y la especialización, se representen
directamente sin que haga falta una compleja traducción al modelo relacional.
3) HERENCIA:
La herencia puede hallarse en el nivel de los tipos o en
el nivel de las tablas. En primer lugar se considerará la
herencia de los tipos y después en el nivel de las
tablas.
Herencia De Tipos. Los métodos de un
tipo estructurado se heredan por sus subtipos, al igual que
los atributos. Sin embargo, un subtipo puede redefinir el
efecto de un método declarando de nuevo el
método, usando overriding method en lugar de method en
la declaración del método.Herencia De Tablas. Las
subtablas pueden guardarse de manera eficiente sin
réplica de todos los campos heredados de una de las
dos siguientes formas:Cada tabla almacena la clave primaria (que se puede
heredar de una tabla padre) y los atributos definidos
localmente. Los atributos heredados (aparte de la clave
primaria) no hace falta guardarlos y pueden obtenerse
mediante una reunión con la súper tabla basada
en la clave primaria.Cada tabla almacena todos los atributos heredados y
definidos localmente. Cuando se inserta una tupla se almacena
sólo en la tabla en la que se inserta y su presencia
se infiere en cada súper tabla. El acceso a todos los
atributos de una tupla es más rápido, dado que
no se requiere una reunión. Sin embargo, en el caso de
que no se considere la segunda restricción de
integridad es decir, una entidad se puede representar en dos
subtablas sin estar presente en una subtabla común de
ambas esta representación puede resultar en
duplicación de información.
Almacenamiento y estructura de
archivos*
1. VISIÓN GENERAL DE LOS
MEDIOS FÍSICOS DE ALMACENAMIENTO:
En la mayor parte de los sistemas informáticos
hay varios tipos de almacenamientos de datos. Estos medios de
almacenamiento se clasifican según la velocidad con
la que se puede acceder a los datos, por el coste de
adquisición del medio por unidad de datos y por la
fiabilidad del medio. Entre los medios disponibles habitualmente
figuran:
Caché. Es la forma de almacenamiento
más rápida y costosa. La memoria caché
es pequeña; su uso lo gestiona el hardware del sistema
informático.Memoria principal. El medio de almacenamiento
utilizado para operar con los datos disponibles es la memoria
principal. Las instrucciones de la máquina de
propósito general operan en la memoria principal. El
contenido de la memoria principal suele perderse si se
produce un fallo del suministro eléctrico o una
caída del sistema.Memoria flash. También conocida como
memoria sólo de lectura programable y borrable
eléctricamente (Electrically Erasable Programmable
Read-Only Memory, EEPROM), la memoria flash se diferencia de
la memoria principal en que los datos pueden sobrevivir a los
fallos del suministro eléctrico.Almacenamiento en discos magnéticos.
El principal medio de almacenamiento a largo plazo de datos
en conexión es el disco magnético. Generalmente
se guarda en este tipo de discos toda la base de datos. Para
tener acceso a los datos hay que trasladarlos desde el disco
a la memoria principal. Después de realizar la
operación hay que escribir en el disco los datos que
se han modificado.

Los medios de almacenamiento más rápidos
(por ejemplo, caché y memoria
principal) se denominan almacenamiento primario. A
continuación un ejemplo ilustrativo:
2. ORGANIZACIÓN DE LOS
ARCHIVOS:
Los archivos se organizan lógicamente como
secuencias de registros. Estos registros se corresponden con los
bloques del disco. Los archivos se proporcionan como un
instrumento fundamental de los sistemas
operativos, por lo que se supondrá la existencia de un
sistema de archivos subyacente. Hay que tomar en
consideración diversas maneras de representar los modelos
lógicos de datos en términos de
archivos.
Un enfoque de la correspondencia entre la base de datos
y los archivos es utilizar varios y guardar los registros de cada
una de las diferentes longitudes fijas existentes en cada uno de
esos archivos.
3. ORGANIZACIÓN DE LOS
REGISTROS EN ARCHIVOS:
Dado un conjunto de registros, la pregunta siguiente es
la manera de organizarlos en archivos. A continuación se
indican varias de las maneras de organizar los registros en
archivos:
Organización de archivos en montículo.
En esta organización se puede colocar cualquier
registro en cualquier parte del archivo en que haya espacio
suficiente. No hay ninguna ordenación de los
registros. Generalmente sólo hay un archivo por cada
relación.Organización de archivos secuenciales. En
esta organización los registros se guardan en orden
secuencial, basado en el valor de la clave de búsqueda
de cada registro.Organización asociativa (hash) de archivos.
En esta organización se calcula una función de
asociación (hash) de algún atributo de cada
registro. El resultado de la función de
asociación especifica el bloque del archivo en que se
deberá colocar el registro.
4. ALMACENAMIENTO PARA LA BASE DE DATOS
ORIENTADAS A OBJETOS:a) Correspondencia de los objetos con los
archivos:
La correspondencia de los objetos con los archivos tiene
gran parecido con la correspondencia de las tuplas con los
archivos de los sistemas relacionales. En el nivel inferior de la
representación de los datos, tanto las partes de tuplas de
los objetos como las de datos, son sencillamente secuencias de
bytes. Por tanto, se pueden guardar los datos de los objetos
utilizando las estructuras de
archivos descritas en los apartados anteriores con algunas
modificaciones que se indican a continuación. Los objetos
de las bases de datos orientadas a objetos pueden carecer de la
uniformidad de las tuplas de las bases de datos relacionales. Por
ejemplo, los campos de los registros pueden ser conjuntos, a
diferencia de las bases de datos relacionales, en los que se
suele exigir que los datos se encuentren (por lo menos) en la
primera forma normal. Además, los objetos pueden ser muy
grandes. Hay que tratar estos objetos de manera diferente de los
registros de los sistemas relacionales. Se pueden implementar
campos de conjuntos que tengan un número pequeño de
elementos que utilicen estructuras de datos como las listas
enlazadas. Los campos de conjuntos que tienen un número de
elementos mayor pueden implementarse como relaciones en la base
de datos. Los campos de conjuntos también pueden borrarse
en el nivel de almacenamiento mediante la normalización:
se crea una relación que contenga una tupla para cada
valor del campo de conjunto de un objeto.
Indexación y
asociación
Un índice para un archivo del
sistema funciona como el índice de este libro. Si se va a
buscar un tema (especificado por una palabra o una frase) en este
libro, se puede buscar en el índice al final del libro,
encontrar las páginas en las que aparece y después
leer esas páginas para encontrar la información que
estamos buscando.
Las palabras de índice están ordenadas, lo
que hace fácil la búsqueda del término que
se esté buscando. Además, el índice es mucho
más pequeño que el libro, con lo que se reduce
aún más el esfuerzo necesario para encontrar las
palabras en cuestión.
Los catálogos de fichas en las
bibliotecas
funcionan de manera similar (aunque se usan poco). Para encontrar
un libro de un autor en particular, se buscaría en el
catálogo de autores y una ficha de este catálogo
indicaría dónde encontrar el libro. Para ayudarnos
en la búsqueda en el catálogo, la biblioteca
guardaría en orden alfabético las fichas de los
autores con una ficha por cada autor de cada libro.
Los índices de los sistemas de bases de datos
juegan el mismo papel que los índices de los libros o los
catálogos de fichas de las bibliotecas. Por ejemplo, para
recuperar un registro cuenta dado su número de cuenta, el
sistema de bases de datos buscaría en un índice
para encontrar el bloque de disco en que se encuentra el registro
correspondiente, y entonces extraería ese bloque de disco
para obtener el registro cuenta.
Almacenar una lista ordenada de números de cuenta
no funcionaría bien en bases de datos muy grandes con
millones de cuentas, ya que el propio índice sería
muy grande; más aún, incluso al mantener ordenado
el índice se reduce el tiempo de búsqueda,
encontrar una cuenta puede consumir mucho tiempo. En su lugar se
usan técnicas
más sofisticadas de indexación.
Por otra parte un inconveniente de la
organización de archivos secuenciales es que hay que
acceder a una estructura de índices para localizar los
datos o utilizar una búsqueda binaria. La
organización de archivos basada en la técnica de
asociación permite evitar el acceso a la estructura
de índice. La asociación también proporciona
una forma de construir índices.
Procesamiento de
consultas
EL procesamiento de consultas hace referencia a la serie
de actividades implicadas en la extracción de datos de una
base de datos. Estas actividades incluyen la traducción de
consultas expresadas en lenguajes de bases de datos de alto nivel
en expresiones implementadas en el nivel físico del
sistema, así como transformaciones de optimización
de consultas y la evaluación
real de las mismas. Los pasos básicos a tomar en cuenta
son:
Análisis y traducción.
Optimización.
Evaluación.
Y los pasos en el procesamiento de una consulta
son:

OPTIMIZACIÓN DE
CONSULTAS
Consiste en el proceso de selección
de las consultas más eficientes de entre las muchas formas
disponibles para el procesamiento de una consulta dada,
especialmente si la consulta es compleja. No se espera que los
usuarios escriban las consultas de modo que puedan procesarse de
manera eficiente. Por el contrario, se espera que el sistema cree
un plan de
evaluación de las consultas que minimice el coste de la
evaluación de las consultas. Aquí es donde entra en
acción la optimización de consultas.
Otro aspecto es la elección de una estrategia para
el procesamiento de la consulta es la selección del
algoritmo que
se utilizará para ejecutar una operación, la
selección de los índices concretos que se van a
emplear entre muchos mas
Transacciones
Muchas veces el usuario de una base de datos utiliza un
conjunto de operaciones sobre dicha base de datos, citando
ejemplos el retiro de dinero de las
diferentes entidades bancarias, etc. Por consiguiente el sistema
de base de datos está compuesto internamente por varias
operaciones.
Evidentemente es esencial que funcionen todas las
operaciones o que, en caso de fallo, ninguna de ellas se
produzca.
Sería inaceptable efectuar el cargo de la
transferencia en la cuenta corriente y que no se abonase en la
cuenta de ahorros.
Se llama transacción a una colección de
operaciones que forman una única unidad lógica de
trabajo. Un
sistema de base de datos debe asegurar que la ejecución de
las transacciones se realice adecuadamente a pesar de la
existencia de fallos: o se ejecuta la transacción completa
o no se ejecuta en absoluto. Además debe gestionar la
ejecución concurrente de las transacciones evitando
introducir inconsistencias.
Para asegurar la integridad de los datos se necesita que
el sistema de base de datos mantenga las siguientes propiedades
de las transacciones:
Atomicidad. O todas las operaciones de la
transacción se realizan adecuadamente en la base de datos
o ninguna de ellas.
Consistencia. La ejecución aislada de
la transacción (es decir, sin otra transacción
que se ejecute concurrentemente) conserva la consistencia de
la base de datos.Aislamiento. Aunque se ejecuten varias
transacciones concurrentemente, el sistema garantiza que para
cada par de transacciones A y B, se cumple que para los
efectos de A, o bien B ha terminado su ejecución antes
de que comience A , o bien que B ha comenzado su
ejecución después de que A termine. De este
modo, cada transacción ignora al resto de las
transacciones que se ejecuten concurrentemente en el
sistema.
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |